6.
Expertensysteme
Zu Beginn dieses Abschnittes wird auf die Definition
des Begriffes Expertensystem eingegangen. Es wird beleuchtet, aus welchen
unterschiedlichen Arten das Wissen eines menschlichen Experten besteht und
wie dieses in einem Computersystem umgesetzt werden kann. Weiters wird die
Motivation diskutiert, Expertensysteme zu erstellen und deren Vor- und
Nachteile beleuchtet. Die Anwendungsgebiete werden anhand von kurzen
Beispielen vorgestellt. In weiterer Folge wird der Entstehungsprozeß eines
Expertensystems und die daran beteiligten Personen sowie deren Funktionen
erklärt. Am Ende dieses Abschnitts wird auf die Arbeitsweise und den
Aufbau eines Expertensystems eingegangen. Dabei wird die
Wissensrepräsentation, die zur Anwendung kommt, vorgestellt und auf die
Techniken eingegangen, in welcher Weise das gespeicherte Wissen
verarbeitet wird.
6.1 Definition von Expertensystemen
Die Erforschung von Expertensystemen stellt eine erfolgreiche Teildisziplin der künstlichen Intelligenz dar. Die Grundidee, die Expertensystemen zugrunde liegt, ist, daß Wissen hochspezialisierter Fachleute in einem Computersystem nachgebildet wird. Auf diese Art sollen menschliche Experten bei Routieneaufgaben unterstützt und entlastet werden. Ein weiteres Ziel ist es, das Wissen, das menschliche Experten durch lernen und jahrelange Erfahrung gesammelt haben, automatisiert verarbeitbar gespeichert wird und somit jederzeit reproduziert werden kann. Zusammengefaßt wird dies in der Definition nach [Puppe1991]:,,Expertensysteme sind Programme, mit denen das Spezialwissen und die Schlußflogerungsfähigkeit qualifizierter Fachleute auf eng begrenzten Aufgabengebieten nachgebildet werden soll.'' [Puppe1991]Dabei geht man von der Vorstellung aus, daß menschliche Experten ihre Problemlösungen aus Einzelkenntnissen zusammensetzten, die sie auswählen und in passender Anordnung anwenden. Ein Expertensystem benötigt daher detailierte Einzelkenntnisse über das Aufgabengebiet und Strategien, wie dieses Wissen zur Lösung eines Problems angewendet werden kann. Um ein Expertensystem zu erstellen, muß das Wissen von einem oder mehreren Experten formalisiert und im Computer repräsentiert werden. Die Form der Wissensrepräsentation, die sich dafür besonders eignet, ist die der logischen Wissensrepräsentation durch Regeln, die in Abschnitt 3.3.1 unter Einfache Fakten Regelsysteme vorgestellt wurde. Die Regeln haben die Form ``Wenn X, dann Y''; z.B. Wenn die Temperatur zu niedrig ist, dann die Heizleistung erhöhen. [Puppe1991]
Zusätzlich zu dieser Wissensrepräsentation muß es in einem Expertensystem auch Möglichkeiten geben, das Wissen (Fakten und Regeln) zu interpretieren bzw. Schlußfolgerungen zu ziehen. Diese Aufgabe übernimmt die Problemlösungskomponente (Inferenzmaschine), die unabhängig vom zu bearbeitenden Wissen ist. Das heißt, das in den Regeln gespeicherte Expertenwissen legt nur fest, was in einer bestimmten Situation getan werden soll, in welcher Reihenfolge die Regeln zu Problemlösung verwendet werden, entscheidet die Inferenzmaschine. [Gottlob1990]
6.2 Zielsetzung und Motivation
Im vorigen Abschnitt wurde der Versuch unternommen, Expertensysteme zu definieren. In diesem Abschnitt sollen nun die Gründe betrachtet werden, Expertensysteme zu entwickeln und deren Zielsetzungen erläutert werden. Die Zielsetzungen für ein Expertensystemprojekt sind: [Gottlob1990]- die Bereitstellung neuer Serviceleistungen, besonders im Dienstleistungsbereich;
- die Entwicklung eines neuen Produktes, entweder als eigenständiges Softwaresystem oder durch Integration eines Expertensystems in ein Analyse- oder Diagnosegerät;
- die Verbesserung von Qualität, Sicherheit, Produktivität und Arbeitsbedingungen - Hauptziele im Rahmen der industriellen Produktion; und
- die Verringerung von Fehleranzahl, Ausschuß und Ressourcenbedarf, d.h. der Versuch, den Produktionsprozeß besser in den Griff zu bekommen.
- der Experte ist mit Aufgaben überlastet, die für ihn Routine sind. Diese Routineaufgaben sollten ihm von einem Expertensystem abgenommen werden, damit er sich den schwierigen Problemen widmen kann;
- der Experte kann nicht vor Ort sein, etwa bei mangelndem Servicepersonal, oder bei Weltraum- und militärischen Projekten;
- es gibt nur einen Experten, der in der Zentrale sitzt. Man möchte jedoch sein Wissen auch in den Filialen verfügbar machen;
- die Anzahl und/oder die Komplexität der Probleme hat so zugenommen, daß der Experte überfordert ist;
- der Experte geht bald in Pension oder wechselt die Firma, man möchte aber sein Wissen nicht mit seinem Ausscheiden verlieren.
- um die Qualität eines Produktes zu erhöhen, liefert man das zugehörige Expertenwissen mit;
- die Problemstellung hat eine Komplexität, die intelligente Unterstützung bei der Problemlösung erfordert;
- die Sicherheit in kritischen Situationen wird erhöht;
- es werden Leistungen an bisher nicht erreichten Orten und/oder Tageszeiten (z.B. Nachts oder am Wochenende) ermöglicht.
6.3 Aufbau von Expertensystemen
Den oben angeführten
Anforderungen an ein Expertensystem kommt das Konzept von wissensbasierten
Systemen, das in Abschnitt 3.2.3
behandelt wurde, entgegen. Bei diesem Konzept existiert eine klare
Schnittstelle zwischen dem gespeicherten Wissen und der
Problemlösungskomponente. Es ist jedoch nicht zwingend vorgeschrieben, daß
Expertensysteme nach diesem Konzept aufgebaut sind. Es wäre auch möglich,
daß die Regeln wie bei konventionellen Programmen fix in den
Programmzeilen zu codieren. Dies würde aber die Reihenfolge der
Abarbeitung der Regeln vorschreiben und die Vorteile der Modularität gehen
verloren.
Die Hauptaufgabe eines Expertensystems ist es, Wissen zu verarbeiten. Aus diesem Grund nehmen die Wissensbasis und der Inferenzmotor im Aufbau eines Expertensystems eine zentrale Rolle ein, wie dies in Abbildung 6.1 dargestellt ist. Zusätzlich muß das System in der Lage sein, über eine Benutzerschnittstelle mit dem Anwender zu kommunizieren und die Ergebnisse zu präsentieren. Das System sollte auch die Fähigkeit besitzen, den Lösungsweg zu analysieren und Entscheidungen zu begründen und zu erklären. Weiters sollten Expertensysteme Möglichkeiten bereitstellen, die Wissensbasis zu erweitern. Nachfolgend sollen die Aufgaben der Komponenten eines Expertensystems erklärt werden, die in Abbildung 6.1 dargestellt sind. [Gottlob1990]
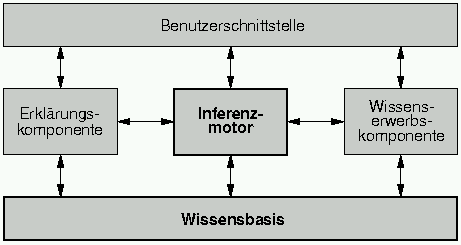 |
- Wissensbasis:
- In der Wissensbasis ist das problembezogene Wissen eines Expertensystems gespeichert. Um die Vorteile der expliziten Wissenspeicherung auszunutzen, sollte in keiner anderen Komponente problembezogenes Wissen gespeichert sein. Der Inhalt der Wissensbasis kann grob unterschieden werden in generisches Wissen, das unabhängig vom aktuellen Anwendungsfall gespeichert ist, und dem fallspezifischen Wissen, das zur Lösung des aktuellen Anwendungsfalls notwendig ist. Lernfähige Systeme können fallspezifisches Wissen, nach der Lösung eines Problems, in den generischen Teil der Wissensbasis aufnehmen. Das generische Wissen umfaßt Fakten zum Problembereich, Wissen über deren Zusammenhänge und deren Schlußfolgerungsmechanismen, und Wissen über Strategien, wie das vorhandene Wissen eingesetzt werden kann.
- Inferenzmotor:
- Der Inferenzmotor stellt die zentrale Problemlösungskomponente dar. Hier werden die, aus der Problemstellung extrahierten Fakten entsprechend der Regeln verknüpft und auf neue Fakten geschlossen. Die Reihenfolge in der dies geschieht, wird von der Inferenzmaschine selbst festgelegt. Nach Beendigung des Schlußflogerungsprozesses werden die neugewonnenen Fakten von der Benutzerschnittstelle aufbereitet und als Lösung des Problems dem Anwender präsentiert.
- Erklärungskomponente:
- Die Erklärungskomponente eines Expertensystems liefert Informationen
über das Zustandekommen der Lösung. Typische Fragestellungen dabei
sind:
- Wie wurde die Lösung eines Problems gefunden?
- Warum wird eine bestimmte Information vom System nachgefragt?
- Warum wurde eine bestimmte Lösung nicht gefunden?
- Wissenserwerbskomponente:
- Die Wissenserwerbskomponente hat die Aufgabe, den Aufbau und die Erweiterung der Wissensbasis zu unterstützen. Sie stellt Funktionen zur Verfügung, die die Konsistenz und Vollständigkeit des gespeicherten Wissens zu überprüfen.
- Benutzerschnittstelle:
- Die Benutzerschnittstelle unterscheidet zwei Arten der Interaktionen mit dem Expertensystem: Die Kommunikation mit dem Anwender, der nach der Lösung eines bestimmen Anwendungsproblems sucht, und der Kommunikation mit dem Knowledge Engineers, das ist die Person, die die Wissensbasis erstellt und wartet. Zu diesem Zweck werden in beiden Fällen die Fakten über die Problemlösung annähernd natürlichsprachlich aufbereitet oder Zusammenhänge graphisch dargestellt.
6.4 Arten von Wissen
Wie bei der Beschreibung der Wissensbasis angedeutet, benötigt ein Expertensystem, wie auch menschliche Experten Wissen, um eine gegebene Problemstellung zu lösen. Das Wissen läßt sich dabei in vier Kategorien einteilen: [Gottlob1990]- Fakten zu einem Problembereich
- sind zumeist in Lehrbüchern enthalten. Sie stellen die Basis dar, auf der das gesamte Teilgebiet aufbaut. Der menschliche Experte eignet sich dieses Wissen in seiner Ausbildung (Studium, Fachausbildung) an, bzw. sucht es bei Bedarf in Wissensspeichern, die meist in gedruckter Form (z.B. Bücher, Manuals, Datenblätter) oder auch elektronisch zur Verfügung stehen. Beispiele für Faktenwissen sind Naturgesetze oder mathematische Gesetze.
- Wissen über die Zusammenhänge der Fakten
- beschreibt festgelegte Verfahrensweisen und deren Auswirkungen. Auch dieses Wissen ist großteils in Lehrbüchern zu finden, z.B. der physikalische Zusammenhang zwischen Luftdruck und Wetter.
- Wissen über Schlußfolgerungsmechanismen und Heuristiken
- für die Lösung von Problemen, eignet sich der Experte durch langjähriges Arbeiten in einem bestimmten Problembereich an. Dieses Wissen stellt das eigentliche Erfahrungswissen menschlicher Experten dar und beinhaltet auch den Umgang mit unvollständigen Informationen und mit Informationen aus den Randbereichen des Aufgabengebietes. Dieses Wissen ist nicht in Lehrbüchern zu finden, wäre auch schwer darin darzustellen, und macht einen Experten deshalb so wertvoll für ein Unternehmen. Wie im nachfolgenden Abschnitt erarbeitet wird, kann Wissen dieser Art nur sehr bedingt in Expertensystemen umgesetzt werden.
- Strategisches Wissen
- ist, wie das Wissen über Schlußfolgerungsmechanismen und Heuristiken, Erfahrungswissen, das sich der Experte im Laufe der Zeit aneignet. Es geht dabei darum, wie man ein Problem angeht, um effizient zu einer Lösung zu gelangen.
6.4.1 Menschlicher Experte versus Expertensystem
Der praktische Nutzen eines Expertensystems für die Wirtschaft besteht in der Möglichkeit, Experten bei Routinetätigkeiten zu entlasten bzw. einfache Probleme auch ohne den Einsatz von Experten zu lösen. Durch Expertensysteme wird es möglich, Expertenwissen automatisiert zu verarbeiten und zu duplizieren, z.B. an andere Firmen weiter zu verkaufen. Weiters besteht die Möglichkeit, Wissen über die Dienstzeit des Experten hinaus zu archivieren, wenn ein Experte in Pension geht oder die Firma wechselt. [Gottlob1990]Im weiteren sollen die Vor- und Nachteile von Expertensystemen erarbeitet werden, in dem die Fähigkeiten von menschlichen Experten denen von Expertensystemen gegenübergestellt werden. Um ein Problem zu lösen, muß ein menschlicher Experte folgende Fähigkeiten besitzen: [Puppe1991]
- Das Problem verstehen
- Das Problem lösen
- Die Lösung erklären
- Randgebiete überblicken
- Seine Kompetenzen bei der Problemlösung einschätzen
- Neues Wissen erwerben und strukturieren
Derzeitige Expertensysteme sind aber nur in der Lage Probleme zu lösen und die Lösung in begrenzten Umfang zu erklären. Die anderen oben erwähnten Fähigkeiten sind für die Ausübung der Tätigkeit eines Experten im allgemeinen genauso wichtig, können aber von den Expertensystemen, die zum Zeitpunkt des Erstellens der vorliegenden Arbeit existieren, nicht erfüllt werden. Würde z.B. ein menschlicher Experte nicht über die Grenzen und Randgebiete seines Spezialgebietes bescheid wissen und nicht in der Lage sein, seine Wissenslücken zu beurteilen, so würde man diesem Experten, nach der ersten darauf beruhenden Fehlentscheidung, nicht mehr vertrauen. [Puppe1991]
Die größte Schwierigkeit eines Expertensystems liegt im Verstehen des Problems. Während menschliche Experten über umfassende sensorische und verbale Fähigkeiten verfügen, um aus der Fülle der Daten die problemrelevanten Umstände herauszufiltern, vorzuinterpretieren und auf ihre Glaubwürdigkeit zu testen, erfordern Expertensysteme eine streng formalisierte Eingabe, deren Korrektheit kaum überprüft werden kann, die aber die Qualität der Problemlösung entscheidend mitbestimmen. Daher eignen sich Expertensysteme vor allem zum Einsatz in solchen Gebieten, bei denen die Datenerfassung wenig fehleranfällig ist, das Expertensystem selbst keine endgültigen Entscheidungen trifft, sondern in einen redundanten Entscheidungsprozeß eingebunden ist, und das Wissen des zu implementierenden Fachbereichs sehr schmal ist. In diesem schmalen Bereich kann das Wissen jedoch sehr tief strukturiert sein. Um Expertensystemen nicht die letzte Entscheidung zu überlassen und ihnen somit nicht eine zu große Verantwortung zu übertragen, werden Expertensysteme häufig dazu verwendet, Lösungen von menschlichen Experten auf ihre Richtigkeit zu überprüfen [Gottlob1990].
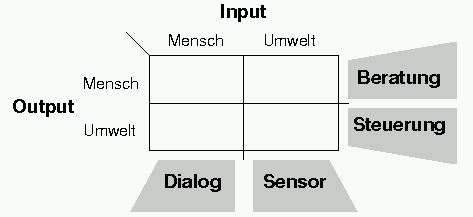
Aus den oben angeführten Gründen lassen sich Expertensysteme nach der Art der Interaktion mit der Umwelt einteilen. Die Einteilung ist in Abbildung 6.2 graphisch dargestellt. Dabei gliedert man Expertensysteme danach, ob der Austausch von Input bzw. Output direkt mit der Umwelt erfolgt oder ob die Interaktion mit der Umwelt über den Umweg eines Menschen stattfindet.
Grundsätzlich gilt für Expertensysteme, je autonomer das System, desto sicherer müssen die Entscheidungen sein. Daher sind Steuernde Systeme dazu gezwungen, bei Entscheidungen ihre Systemgrenzen zu überprüfen. Die Erklärungskomponente kann bei solchen Systemen unter Umständen entfallen. Sensorgeführte Systeme müssen in der Lage sein, Datenfehler zu erkennen und zu korrigieren. Bei der Erstellung eines Dialoggeführten Systems muß ein Modell der Benutzergruppe berücksichtigt werden, um damit festzulegen, welche Daten sinnvollerweise vom Benutzer erhoben werden können, bzw. welche Art der Erklärung für die Beratung notwendig ist. Dialoggeführte Beratungssysteme stellen den überwiegenden Teil der Expertensystemanwendungen dar. Nicht zuletzt ist dies darauf zurückzuführen, daß auf der Inputseite der Mensch für die Vorabverarbeitung der Daten sorgen muß, und auf der Outputseite der Expertensystementwickler die letztenscheidung und somit auch die Verantwortung gerne dem Menschen überläßt. [Gottlob1990]
 |
- Urteilsfähigkeit:
- Die Urteilsfähigkeit eines Expertensystems ist immer gleich, das bedeutet, Expertensysteme kennen keinen Einfluß von Streß oder anderen emotionalen Faktoren. Ermüdung und Langeweile, wie sie bei Menschen bei Überwachungsaufgaben vorkommen, sind für Expertensysteme kein Problem. Ein Expertensystem kann daher auch unter extremen Bedingungen eingesetzt werden.
- Wissenstransfer:
- Bei der Erstellung eines Expertensystems ist es notwendig, daß das Wissen von Experten explizit dargestellt und dokumentiert wird. Dieses Wissen kann somit auch anderen Leuten (Laien) zum Lernen zu Verfügung gestellt werden. Dies kann z.B. durch die Erklärungskomponente des Systems geschehen.
- Verbreitung:
- Expertenwissen kann mit Hilfe eines Expertensystems viel leichter verbreitet werden. Dazu ist nur das Kopieren des Systems auf eine anderen Rechner nötig.
- Kosten:
- Da nur die Entwicklung eines Expertensystems größere Kosten verursacht, ein fertiges Expertensystem praktisch kostenlos dupliziert werden kann, ist der Einsatz von Expertensystemen billiger als die Ausbildung eines menschlichen Experten.
6.5 Anwendungsgebiete von Expertensystemen
In der Geschichte der künstlichen Intelligenz wurde der Weg von der Suche nach allgemeinen Problemlösern hin zu stark problemspezifischen Ansätzen beschritten. Es wurde erkannt, daß für unterschiedliche Problemtypen unterschiedliche Lösungsansätze notwendig sind [Russell1995]. Expertensysteme sind die Konsequenz aus dieser Entwicklung. Ihr Ziel ist es, Probleme auf einem stark eingeschränkten Anwendungsgebiet zu lösen. Dabei können folgende Problemtypen unterschieden werden [Puppe1991]:- Interpretation:
- Ableitung einer Situationsbeschreibung aus Sensordaten. (z.B. Geologie - Aus den Daten von Probebohrungen wird die Struktur der geologischen Formation ermittelt)
- Diagnostik:
- Ableitung von Systemfehlern aus Beobachtungen; Erkennen von Ursachen. (z.B. Erstellen von medizinischen Diagnosen.)
- Überwachung:
- Vergleich von Beobachtungen mit Sollwerten. (z.B. Patient Monitoring in der Medizin - Das System erhält laufend Daten des Patienten und vergleicht diese mit Sollwerten. Bei einer Abweichung schlägt das System Alarm.)
- Steuerung:
- Vergleich von Beobachtungen mit Sollwerten und Veranlassen von Aktionen. (z.B. Patient Monitoring in der Medizin - Ähnlich der Vorgehenswiese bei der Überwachung, jedoch setzt das System selbst Handlungen, um den kritischen Zustand zu beseitigen.)
- Design:
- Konfiguration von Produkten unter bestimmten Voraussetzungen. (z.B. Chemie - Herstellung komplexer organischer Moleküle, integrierte Schaltungen, usw.)
- Planung:
- Entwurf einer Folge von Aktionen zum Erreichen eines Ziels. (z.B. Technik - Zusammenstellung eines Reperaturplanes bei einem Maschinenschaden) In der Produktionsplanung lassen sich dadurch die vorhandenen Ressourcen optimal einsetzen.
- Vorhersage:
- Ableitung von möglichen Konsequenzen gegebener Situationen. (z.B. Wirtschaft - Ausgehend von der derzeitigen geopolitischen Lage wird der zukünftige Bedarf an Rohöl geschätzt)
- Diagnostik:
- Das Ziel der Diagnose ist es, ein bekanntes Muster, wie z.B. ein Krankheitsbild oder einen Fehler, wieder zuerkennen. Dabei wird die Lösung aus einer vorgegebenen Menge von Alternativen ausgewählt.
- Konstruktion:
- Bei der Konstruktion wird die Lösung aus kleinen Bausteinen zusammengesetzt. Es gibt jedoch zuviele mögliche Kombinationen, um aus der Menge aller vorgegebener Alternativen auszuwählen. So kann z.B. bei der automatisierten Programmierung nicht aus der Menge aller möglichen Programme ausgewählt werden. Stattdessen sind bestimmte Fakten im System Modulen zugeordnet, die entsprechend kombiniert werden. Das Expertensystem hat somit die Aufgabe gezielt nach Fakten der Aufgabenstellung zu fragen, um die notwendigen Module so zu kombinieren, daß die Aufgabenstellung erfüllt ist.
- Simulation:
- Die Simulation unterscheidet sich von der Diagnose und der Konstruktion dadurch, daß kein vorgegebenes Ziel erreicht werden soll, sondern nur die Auswirkungen von Handlungen und Entscheidungen simuliert werden sollen. Es werden somit von einem Ausgangszustand die möglichen Folgezustände hergeleitet.
6.5.1 Praktische Anwendungen von Expertensystemen
Die Entwicklung von Expertensystemen begann im Jahre 1965. Nach über 10 Jahren der Forschung begannen Expertensysteme ab den 80er Jahren an wirtschaftlicher Bedeutung zu gewinnen. Im folgenden sind einige Meilensteine in der Geschichte von Expertensystemen angeführt [Puppe1991][Gottlob1990]:- DENTRAL wurde als eines der ersten Systeme an der Stanford University, Lindsay entwickelt und ist ein System zur Strukturanalyse organischer Substanzen. Die zu interpretierenden Daten werden aus dem Massenspektrogramm gewonnen.
- MYCIN wurde ebenfalls an der Stanford University entwickelt und ist ein System zur Diagnose und Therapie von bakteriellen Infektionskrankheiten des Blutes. In MYCIN ist das Wissen in über 450 Regeln gespeichert. MYCIN zeichnet sich zusätzlich durch seine klare Trennung zwischen Wissensrepräsentation und Inferenzmaschine aus. Die Entwicklung dieser Technik machte es möglich, daß in weiterer Folge das medizinische Wissen aus MYCIN entfernt wurde und die Inferenzmaschine unter dem Namen EMYCIN als Grundlage für andere Expertensysteme diente. EMYCIN war somit die erste Expertensystem-Shell.
- PROSPECTOR ist ein geologisches System zur Interpretation von Meßdaten aus Probebohrungen. Ziel ist es herauszufinden, ob ein bestimmtes Mineral in einer Region vorhanden ist oder nicht.
- XCON war bei Digital im Einsatz und diente zur Konfiguration von VAX Rechneranlagen. Ausgehend von der Bestellung einer Rechneranlage stellte XCON sicher, daß alle erforderlichen Komponenten vorhanden waren und sorgte für das korrekte Zusammenspiel der Komponenten inklusive der Verkabelung. XCON baute auf mehr als 2000 Regeln auf und war das erste erfolgreiche System dieser Größenordnung.
6.6 Entwicklungsstufen eines Expertensystems
Der Wissenserwerb umfaßt die Identifikation, Formalisierung und Wartung des Wissens, das ein Expertensystem benötigt, um Probleme lösen zu können und stellt zur Zeit den Falschenhals bei der Entwicklung von Expertensystemen dar. Der Erfolg eines Expertensystem hängt entscheidend vom Umfang und der Qualität der Mitarbeit der beteiligten Experten ab, an die hohe Anforderungen gestellt werden. Aufbau und Wartung einer Wissensbasis erfordern, daß sowohl objektive Fakten aus Lehrbüchern als auch subjektives Expertenwissen eingebracht wird. Es sollen möglichst vielfältige Wissensquellen zur guten Abdeckung des Fachbereiches verwendet werden. [Gottlob1990]6.6.1 Beteiligte Personen am Wissenserwerb
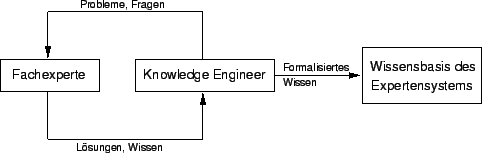
Wie bereits oben erwähnt, sind ein oder mehrere Personen notwendig, um Wissen für den Aufbau eines Expertensystems zur Verfügung zu stellen. Dieses Wissen muß formalisiert und in maschinengerechter Form dargestellt werden. Da die meisten Fachexperten aber keine Informatiker sind, fällt diese Aufgabe dem sogenannten Knowledge Engineer zu. Der Knowledge Engineer stellt somit das Bindeglied zwischen den menschlichen Experten und dem Computer dar.Die Aufgabe des Knowledge Engineer ist es nun, dem Experten sein Wissen möglichst vollständig zu entlocken. Dieses Wissen muß danach strukturiert und formal dargestellt werden. Abbildung 6.3 veranschaulicht diesen Vorgang. Das Hauptproblem an dieser Vorgangsweise ist es, möglichst viel Wissen zu extrahieren. Für die Befragung der Experten durch den Knowledge Engineer haben sich bestimmte Interviewtechniken herausentwickelt. [Puppe1991]
 |
- Unstrukturiertes (traditionelles) Interview: Während der Experte über das Wissen spricht oder Testfälle löst, stellt der Wissensingenieur mehr oder weniger spontane Fragen.
- Laut Denken Modell: Der Experte denkt laut, während er ein Problem löst und erläutert die einzelnen Schritte.
- Introspektion: Der Experte beschreibt von sich aus wie er einen Fall löst oder welche Problemlösungsstrategie er benutzt. Im Gegensatz zum Laut Denken Modell beschreibt er bei der Introspektion eine Zusammenfassung seines Problemlösungsverhalten, nachdem er einen Fall gelöst hat.
- Strukturiertes Interview: Protokolle, die mit einer der anderen Interviewmethoden bereits erstellt wurden, werden von demselben oder von einem anderen Experten kommentiert und eingeschätzt.
Ein wichtiges Kriterium von Testfällen, vor allem für Laut-Denken-Protokolle, ist die Ähnlichkeit des Falles mit der realen Problemsituation des Experten. Ein anderes Kriterium ist der Schwierigkeitsgrad des Falles. Daraus ergeben sich folgende Arten von Testfällen: [Puppe1991]
- Typische Fälle, die der Experte routinemäßig löst.
- Fälle mit begrenzter Informationsangabe: Dabei werden dem Experten bestimmte, normalerweise vorhandene Informationen vorenthalten, um die Bedeutung von Einzelinformationen herauszufinden.
- Fälle mit Beschränkung der Verarbeitungskapazität: Mögliche Beschränkungen sind die Zeit, die dem Experten zur Verfügung gestellt wird, oder bestimmte Fragestellungen, auf die sich der Experte konzentrieren soll.
- Schwierige Fälle, die der Experte nicht routinemäßig lösen kann: Zu schwierigen Fällen wird man übergehen, wenn die Basisproblemlösungsstrategien bereits identifiziert sind.
6.6.2 Schwierigkeiten beim Wissenserwerb
Obwohl der Begriff Knowledge Engineer, auch Wissensingenieur, nahelegt, daß die Extraktion des Wissens von Experten eine im Prinzip gut verstandene Tätigkeit sei, trifft eher das Gegenteil zu, sodaß man eher von ,,Wissenskünstlern'' sprechen sollte. [Puppe1991]Eine der Hauptursachen ist die unvermeidliche Unvollständigkeit der verbalen Daten von Experten. Gründe dafür sind: [Puppe1991]
- Experten vergessen meist viele wichtige Faktoren zu nennen, da sie diese für selbstverständlich halten oder das Wissen nicht durch entsprechende Reize aktiviert wird.
- Komplexere Wissensbereiche, vor allem bildhaftes Wissen, können verbal kaum adäquat beschrieben werden.
- Teile des Wissens können unbewußt sein.
- In der Sprache wird viel Wissen durch Referenz auf als bekannt vorausgesetztes Wissen kommuniziert. Dieses Wissen muß der Knowledge Engineer auf Grund seines Verständnisses des Problembereiches ergänzen. Dieser Vorgang ist sehr problematisch.
- Experten können aus vielen Gründen nicht dazu bereit sein, ihr Wissen preiszugeben.
- Viele Experten haben Schwierigkeiten, ihre Vorgehensweise zu erklären. Das ist auch für Laut-Denken-Protokolle kritisch, die nur dann einen Wert haben, wenn durch das laute Denken das Problemlösungsverhalten des Experten nicht wesentlich beeinflußt wird.
6.6.3 Entwicklungsphasen eines Expertensystems
Als beste Vorgangsweise zur Erstellung eines Expertensystems erweist sich eine evolutorische, inkrementelle Entwicklungsstrategie, die von einfachen zu komplexen Problemstellungen führt, wobei die Organisation und Repräsentation des Systems ständig verbessert und erweitert werden. Es wird möglichst rasch ein einfaches, lauffähiges System hergestellt, um durch Experten-Feedback den weiteren Entwicklungsfortgang in geeignete Bahnen zu lenken. Der Entwicklungskreislauf eines Expertensystems ist in Abbildung 6.4 dargestellt. Diese Vorgehensweise nennt man Rapid Prototyping oder Incremental Development. [Gottlob1990]
 |
In der nachfolgenden Auflistung werden die Entwicklungsphasen bei der Erstellung eines Expertensystems detailierter betrachtet: [Schnupp1986]
- Erstes Design der Wissensbasis
- Problemidentifikation: Definition von Zielen, Einschränkungen, Ressourcen, der teilnehmenden Personen und ihrer Rollen.
- Konzeption: Detailierte Beschreibung der Problemstellung und wie sie in Unterprobleme zerlegt werden kann. Beschreibung der Elemente zur Problemlösung in Form von Hypothesen, Fakten und Lösungsstrategien.
- Formalisierung: Wahl einer Wissensrepräsentation im Computer für die in der Konzeption identifizierten Elemente. Hier kommen zum ersten Mal Implementierungsüberlegungen zum Tragen.
- Implementation und Test eines Prototyps
Ist einmal eine geeignete Wissensrepräsentation gewählt, kann mit der Implementierung eines Prototyps begonnen werden, der einen Teilbereich des endgültigen Systems umfaßt. Die richtige Auswahl des Bereiches ist von großer Bedeutung. Dieser muß Repräsentativ für das Gesamtsystem, aber einfach zu testen sein.
Sobald der Prototyp akzeptable Ergebnisse produziert, kann er auf detailliertere Varianten des Zentralproblems erweitert und mit komplexen Fällen getestet werden.
- Verfeinerung und Generalisierung der Wissensbasis
Diese Phase kann sehr viel Zeit beanspruchen, bis das gewünschte Expertenniveau erreicht ist. Die Grundstrukturen liegen hier bereits fest, es wird eigentlich ,,nur'' mehr das System mit detailliertem, verfeinertem Wissen erweitert.
- Implementierung der Mensch-Maschine Schnittstelle
In dieser Phase wird eine dem Problem entsprechende komfortable Benutzerschnittstelle entwickelt. Die bisher verwendete Benutzerschnittstelle diente dem Knowledge Engineer zu Testzwecken und ist deshalb in viele Fällen nur sehr sporadisch ausgeführt. Weiters erfolgt in dieser Phase, die Erstellung der Dokumentation, der Wartungs- und Schulungsunterlagen.
- Einführung des Systems in das Unternehmen
Das Expertensystem wird in dieser Phase in die vorhandene Informations-Technologie (IT) des Unternehmen eingebunden. Dazu zählt nicht nur die Installation auf den Arbeitsplatzrechnern, sondern auch die Schulung der zukünftigen Benutzer. Erfahrungen und Hinweise der Benutzer sollen aufgezeichnet werden und bei der laufenden Verbesserung und Verfeinerung des Expertensystems berücksichtigt werden.
6.7 Wissensverarbeitung in Expertensystemen
In diesem Abschnitt soll erläutert werden, in welcher Form Wissen in Expertensystemen gespeichert wird und wie das gespeicherte Wissen verknüpft wird, um auf neues Wissen zu schließen. Anhand von Beispielen werden dabei zwei grundlegende Methoden der Wissensverarbeitung in Expertensystemen, die Vorwärtsverkettung und die Rückwärtsverkettung, vorgestellt. [Puppe1991]6.7.1 Wissensspeicherung
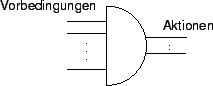
Da Experten Wissen oft in Form von Regeln formulieren, wird in Expertensystemen meist eine logische Wissensrepräsentation durch Fakten und Regeln verwendet. Regeln bestehen aus einer Vorbedingung und einer Aktion. Vorbedingungen bestehen wiederum aus der Verknüpfung von ein oder mehreren Fakten. Nachfolgend sind zwei Beispiele für Regeln angegeben:
| Regel 1 | Wenn | Nackensteife und |
| hohes Fieber und | ||
| Bewußtseinstrübung zutreffen | ||
| Dann | besteht der Verdacht auf Meningitis | |
| Regel 2 | Wenn | Verdacht aud Meningitis besteht |
| Dann | Nimm sofort Antibiotika |
In Regel 1 sind ,,Nackensteife'', ,,hohes Fieber'' und ,,Bewußtseinstrübung'' die verknüpften Fakten und ,,besteht der Verdacht auf Meningitis'' die Aktion.
Wenn man die Aktionen der beiden Beispielregeln betrachtet, stellt man fest, daß es sich dabei um zwei unterschiedliche Arten von Aktionen handelt. Bei ,,besteht der Verdacht auf Meningitis'' handelt es sich um eine Hypothese, die dann wahr ist, wenn alle Fakten zutreffen. Man spricht von Implikation6.1 oder Deduktion6.2. In Regel 2 entspricht die Aktion ,,Nimm sofort Antibiotika'' einer Handlung. [Puppe1991]
Zusammenfassend kann man sagen, die Regeln eines Expertensystems bestehen aus: [Winston1993]
- Vorbedingungen (engl. antecedents), die aus der Verknüpfung ein oder mehrerer Fakten zusammengesetzt sind,
- und aus ein oder mehreren Aktionen (engl. conclusions). Bei
den Aktionen unterscheidet man zwei Arten: [Winston1993]
- Implikationen oder Deduktionen, mit denen der Wahrheitsgehalt einer Hypothese hergeleitet wird; z.B. Regel 1. Expertensysteme deren Aktionen Implikationen oder Deduktionen sind nennt man Deduction Systems.
- Handlungen, mit denen ein Zustand verändert wird; z.B. Regel 2. Expertensysteme deren Aktionen Handlungen sind, nennt man Reaction Systems.
 |
Um die Strukturierung und die Überschaubarkeit der Wissensbasis zu erhöhen, ist es zumeist möglich zusammengehörende Regeln, das sind Regeln, die einen bestimmten Teil des Problems behandeln, zu sogenannten Wissensinseln zusammenzufassen, das heißt, ein Teilproblem wird von einer Wissensinsel gelöst und kann unter Umständen andere Wissensinseln dabei aktivieren oder von anderen Wissensinseln aus aktiviert werden. Oft ist es auch möglich, die Wissensinseln in eigene Teil-Wissensbasen zu legen, die nur dann in den Computer geladen werden, wenn das zugehörige Teilproblem gerade behandelt wird. Diese Strukturierung reduziert die im Computer aktuell zu untersuchenden Regeln und steigert so die Performance eines Expertensystems. [Gottlob1990]
Nach der Betrachtung der Wissensspeicherung soll nun betrachtet werden, wie diese Regeln intern abgearbeitet werden, um mit den vorhandenen Fakten zu neuen Schlußfolgerungen zu kommen. Es gibt zwei prinzipielle Arten der Regelverarbeitung: Die Vorwärtsverkettung und die Rückwärtsverkettung.
6.7.2 Wissensverarbeitung:
Vorwärtsverkettung
Bei der Vorwärtsverkettung (forward chaining)
leitet der Regelinterpreter alle Schlußfolgerungen her, die aus den, dem
Expertensystem bekannten Fakten, herleitbar sind, das heißt, das System
prüft alle Regeln, deren Vorbedingungen erfüllt sind und arbeitet diese
Regeln ab. Zu einer Regel die abgearbeitet wird und deren Vorbedingung
erfüllt ist, sagt man auch die Regel ,,feuert''. Danach prüft das System
wieder, welche Regeln abgearbeitet werden können. Dies soll anhand eines
Beispiels, das in Abbildung 6.6
dargestellt ist, veranschaulicht werden. [Winston1993]
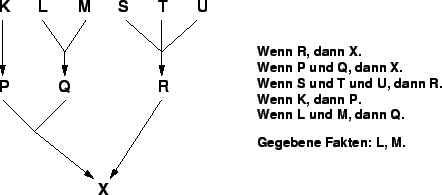 |
6.7.3 Wissensverarbeitung: Rückwärtsverkettung
Während man mit der Vorwärtsverkettung nur Schlußfolgerungen aus einer vorgegebenen Faktenmenge beziehen kann, eignet sich ein rückwärtsverkettender Regelinterpreter (Backward Chaining) auch zum gezielten Erfragen noch unbekannter Fakten. Ein Backward Chaining Regelinterpreter startet mit einem vorgegebenen Ziel. Wenn das Ziel nicht in der Menge der bekannten Fakten vorkommt, entscheidet der Regelinterpreter zunächst, ob es abgeleitet werden kann oder ob es erfragt werden muß. Ein Faktum kann dann abgeleitet werden, wenn zumindest eine Regel existiert, in der das Faktum auf der rechten Seite, der Seite der Aktion, vorkommt. Existiert keine solche Regel, bleibt dem System nur die Möglichkeit, dieses Faktum vom Anwender zu erfragen. [Winston1993]Im Falle der Ableitung werden alle Regeln abgearbeitet, in deren Aktionsteil das Ziel enthalten ist. Wenn bei der Überprüfung der Vorbedingungen einer Regel ein Parameter unbekannt ist, wird ein Unterziel zur Bestimmung dieses Parameters generiert und der Backward Chaining Mechanismus zur Bestimmung dieses Unterziels rekursiv herangezogen. Das Endergebnis ist die Bestimmung eines Wertes für das vorgegebene Ziel und für alle Unterziele, die Evaluierung der relevanten Regeln und das Stellen der notwendigen Fragen. Die Rückwärtsverkettung enthält implizit eine Dialogsteuerung, wobei die Reihenfolge der gestellten Fragen von der Reigenfolge der Regeln zur Herleitung eines Parameters und von der Reihenfolge der Aussagen in der Vorbedingung einer Regel abhängt. Je präziser das Ziel, desto kleiner der Suchbaum von zu überprüfenden Regeln und zu stellenden Fragen. Als Beispiel für die Veranschaulichung dient wieder das Regelsystem aus Abbildung 6.6.
Beim Backward Chaining wird ein vorgegebenes Ziel aktiv bewiesen. In unserem Fall soll es das Faktum X sein. Es existieren zwei Wege zum Bewiesen von X. Der eine führt von X über R nach S, T und U. Der zweite führt von X nach P und Q und dann nach K bzw. L und M.
Nehmen wir an, daß der Regelinterpreter zuerst den ersten Weg zum Beweisen von X durchsucht. Es gibt eine Regel, die X beweisen kann, nämlich ,,Wenn R dann X''. R ist nicht in der Menge der bekannten Fakten, deshalb wird als neues Ziel R etabliert und der Backward Chaining Mechanismus auf R angewendet. Auch für R existiert eine Regel, nämlich ,,Wenn S und T und U, dann R''. Weder S,T noch U sind in der Menge der bekannten Fakten, deshalb muß der Regelinterpreter S,T und U ermitteln. Da aber für diese Fakten keine Regeln zu deren Ermittlung zur Verfügung stehen, muß der Regelinterpreter diese Fakten vom Benutzer erfragen. Werden alle Fakten S ,T und U vom Benutzer als gegeben eingegeben, so wird R zu wahr und in letzter Konsequenz auch X zu wahr. Damit ist X bewiesen und der Regelinterpreter kann aufhören zu arbeiten, da er das vorgegebene Ziel beweisen konnte.
Wird nun eine der Fakten S, T oder U vom Benutzter als nicht bekannt eingegeben, kann R nicht bewiesen werden und aus dem ersten Suchweg auch X nicht als wahr bewiesen. Somit muß der Regelinterpreter auch noch den zweiten Weg über P, Q und K, L und M zum Beweisen des Faktums X durchlaufen. Dies geschieht in derselben Weise wie dies beim ersten Weg gezeigt wurde. Das heißt, zum Beweisen von X müssen P und Q bekannt sein. Q kann aus den gegebenen Fakten L und M (sind schon in der Menge der gegebenen Fakten) zu wahr ermittelt werden. P wird durch Erfragen des Faktums K vom Benutzer ermittelt. Wird das Faktum K als gegebenes Faktum vom Benutzer angegeben, so wird P zu wahr. Aus den Fakten P und Q kann somit X zu wahr bewiesen und in die Menge der bewiesenen Fakten aufgenommen werden.
6.7.4 Vorwärtsverkettung versus Rückwärtsverkettung
Während in Reaction Systems immer die Vorwärtsverkettung verwendet wird, kann ein Deduction System entweder mit Vorwärtsverkettung oder Rückwärtsverkettung arbeiten. Welche Art der Verkettung nun tatsächlich verwendet wird, hängt von der Art der Anwendung ab. [Winston1993]Für die Vorwärtsverkettung wird man sich entscheiden, wenn viele Fakten sehr wenigen Regeln gegenüber stehen, oder alle möglichen Fakten vorgegeben sind und man alle daraus ableitbaren Schlußfolgerungen wissen möchte. [Winston1993]
Wenn die gegebenen oder eruierbaren Fakten zu einer großen Anzahl von Schlüssen führen, aber die Anzahl der Wege zum gewünschten Ziel klein ist, sollte man auf Rückwärtsverkettung zurückgreifen. Würde man Vorwärtsverkettung anwenden, würden viel Regeln abgearbeitet, deren Ergebnis schlußendlich nicht weiter benötigt wird. Ein Anwendungsfall für Rückwärtsverkettung ist, wenn keine oder wenige Fakten bekannt sind und man ein oder mehrere Hypothesen beweisen möchte. [Winston1993]
6.7.5 Konfliktlösungstrategien
Wie oben gezeigt wurde, kann es vorkommen, daß mehrere Regeln gleichzeitig feuerbereit sind. Da aber immer nur eine Regel feuern kann, muß eine Regel aus dieser Menge der feuerbereiten Regeln ausgewählt und bearbeitet werden. Die Menge der feuerbereiten Regeln bezeichnet man als Konfliktmenge und die Auswahl einer bestimmten Regel aus dieser Menge als Konfliktlösungsstrategie. Bei der Konfliktlösungsstrategie unterscheidet man folgende Methoden: [Winston1993]- Auswahl nach der Reihenfolge
- Die erste anwendbare Regel feuert (Trivialstrategie)
- Die aktuellste Regel feuert, d.h. die Regel, deren Vorbedingungen sich auf möglichst neue Einträge in der Faktenmenge bezieht.
- Auswahl nach der syntaktischen Struktur der Regel
- Die spezifischste Regel feuert, d.h. die Regel, deren Vorbedingung die einer anderen Regel als Vorbedingung vorkommt und noch noch mit zusätzlichen Aussagen verknüpft ist.
- Die syntaktisch größte Regel feuert, d.h. die, die meisten Aussagen in der Vorbebingung enthält
- Auswahl mittels Zusatzwissen
- Die Regel mit der höchsten Priorität feuert. Dazu muß jeder Regel eine Priorität, die z.B, als Zahl repräsentiert sein kann, zugeordnet werden.
- Zusätzliche Regeln, sogenannte Meta-Regeln steuern den Auswahlprozeß.
6.8 Certainty Factor
Abschließend soll in diesem
Kapitel die Möglichkeit betrachtet werden, unsicheres Wissen mit der Hilfe
von Regeln zu repräsentieren und zu verarbeiten. Auf die Quellen von
Unsicherheit wurde bereits in Abschnitt 3.8
eingegangen. In diesem Abschnitt sollen nun die Certainty Factors, als
Möglichkeit unsicheres Wissen in Fakten Regelsystemem zu berücksichtigen,
vorgestellte werden.
Beim Prinzip der Certainty Factors handelt es sich um ein intuitives Konzept, welches in engen Zusammenhang mit dem Expertensystem MYCIN entwickelt wurde. Dabei unterscheidet man zwei grundsätzlich verschiedene Arten von Certainty Factors: [Gottlob1990][Heinsohn1999]
- Dynamischer Certainty Factor:
- Der dynamische Certainty Factor wird dazu verwendet, die Sicherheit
von Fakten, die nicht als definitiv wahr oder falsch bekannt sind,
quantitativ zu bewerten. Dem Faktum wird dabei ein Zahlenwert aus dem
Intervall
![$[-1,1]$](Reif-node8-Dateien/img277.gif) zugeordnet. Der Zahlenwert
zugeordnet. Der Zahlenwert 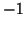 entspricht dabei definitiv falsch, der
Wert
entspricht dabei definitiv falsch, der
Wert 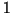 definitiv richtig.
definitiv richtig.
Meist basieren diese quantitativen Bewertungen von Fakten auf einem bestimmten Hintergrundwissen, welches in diesem Zusammenhang als Evidenz
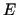 bezeichnet wird. Im Laufe der Bearbeitung des Problems
fließt neues Wissen in Form von Fakten in die Wissensbasis des Systems
ein. Im Rahmen dieses Prozesses ändert sich die Evidenz und somit unter Umständen auch
die Certainty Factors, die den Fakten zugeordnet sind. Der Certainty
Factor
bezeichnet wird. Im Laufe der Bearbeitung des Problems
fließt neues Wissen in Form von Fakten in die Wissensbasis des Systems
ein. Im Rahmen dieses Prozesses ändert sich die Evidenz und somit unter Umständen auch
die Certainty Factors, die den Fakten zugeordnet sind. Der Certainty
Factor 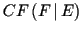 entspricht somit der Sicherheit des Faktums
entspricht somit der Sicherheit des Faktums 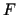 auf Basis der Evidenz . Da sich, wie oben erläutert, die
Certainty Factors im Zuge der Wissensverarbeitung laufend verändern,
spricht man von dynamischen Certainty Factors.
auf Basis der Evidenz . Da sich, wie oben erläutert, die
Certainty Factors im Zuge der Wissensverarbeitung laufend verändern,
spricht man von dynamischen Certainty Factors. - Fester Certainty Factor:
- Der feste Certainty Factor tritt in Zusammenhang mit Regeln auf. Mit
seiner Hilfe wird die unsichere Abhängigkeit zwischen der Vorbedingung
(Prämisse) und der Aktion (Konklusion) ausgedrückt. Die Vorbedingung
kann dabei auch aus der komplexen Verknüpfung von unsicheren Fakten
bestehen. Ein Beispiel für eine solche Regel ist:
Wenn Nackensteife und hohes Fieber und Bewußtseinstrübung zutreffen Dann besteht der Verdacht (0.7) auf Meningitis Diese Regel drückt die bedingte Sicherheit aus, daß es sich bei der Krankheit um Meningitis handelt. Der Certainty Factor
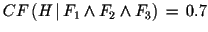 repräsentiert die bedingte Sicherheit der
Hypothese
repräsentiert die bedingte Sicherheit der
Hypothese 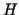 unter der Bedingung, daß die Fakten
unter der Bedingung, daß die Fakten 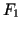 ,
, 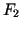 und
und 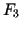 wahr sind. Die festen Certainty Factors werden bei der
Erstellung der Regelbasis von den Fachexperten den Regeln
zugeordnet.
wahr sind. Die festen Certainty Factors werden bei der
Erstellung der Regelbasis von den Fachexperten den Regeln
zugeordnet.
- Die Abarbeitung der Regen erfolgt nach dem in Abschnitt 6.7.2 vorgestellten Schema. Die dynamischen Certainty Factors der bekannten Fakten werden dabei vom Benutzer in das System eingegeben.
- Im Fall einer komplexen zusammengesetzten Prämisse wird aus den Certainty Factors der einzelnen Fakten der Certainty Factor der zusammengesetzten Prämisse berechnet.
- Ist der dynamische Certainty Factor der Prämisse bekannt, kann unter Einbeziehung des festen Certainty Factors der Regel die Regelanwendung erfolgen. Der Sicherheitsfaktor der Hypothese wird berechnet und stellt das zum jetzigen Zeitpunkt über die Hypothese bekannte Wissen dar.
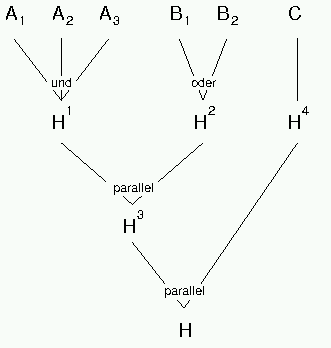
- Ein und die selbe Hypothese wird unter Umständen durch mehrere Regeln bewertet. Das bedeutet die Hypothese kommt in mehreren Regeln als Aktion vor. Die Anwendung dieser Regeln führt somit auch zu mehreren Certainty Factors, die die Sicherheit derselben Hypothese bewerten. Den Vorgang, der diese Einzelbewertungen zusammenfaßt, bezeichnet man als parallele Kombination.
| Regel 1: | |||
| Regel 2: | |||
| Regel 3: |
Als erste anwendbare Regel wird die Regel 1 angenommen. Regel 1 kann
angewendet werden, wenn die Certainty Factors der
Prämissenelemente ![]() ,
,![]() und
und ![]() bekannt sind. Auf der Basis der einzelnen Certainty Factors
bekannt sind. Auf der Basis der einzelnen Certainty Factors ![]() kann der Certainty Factor
kann der Certainty Factor ![]() der zusammengesetzten Prämisse berechnet
werden.
der zusammengesetzten Prämisse berechnet
werden. ![]() ist die Evidenz zu den Bewertungen der Fakten
ist die Evidenz zu den Bewertungen der Fakten ![]() . Es erfolgt die Regelanwendung, die zu dem
Wert
. Es erfolgt die Regelanwendung, die zu dem
Wert ![]() führt.
führt. ![]() ist hier die Bewertung der
Hypothese
ist hier die Bewertung der
Hypothese ![]() nach der erfolgten Anwendung der ersten Regel. Analog erfolgt die
Anwendung von Regel 2 auf der Basis der Bewertungen
nach der erfolgten Anwendung der ersten Regel. Analog erfolgt die
Anwendung von Regel 2 auf der Basis der Bewertungen ![]() und die Berechnung von
und die Berechnung von ![]() .
. ![]() ist die Evidenz zu den Bewertungen der Fakten
ist die Evidenz zu den Bewertungen der Fakten ![]() .
.
Als Ergebnis der Anwendung von Regel 1 und 2 können nun die Certainty
Factors ![]() und
und ![]() der Hypothese
der Hypothese ![]() parallel kombiniert werden und erhält somit
das zusammengefaßte
Ergebnis
parallel kombiniert werden und erhält somit
das zusammengefaßte
Ergebnis ![]() .
.
Auf analoge Weise kann Regel 3 angewendet werden und in die bereits
berechneten Werte einbezogen werden. Man erhält abschließend den Certainty
Factor ![]() wobei
wobei ![]() die der Bewertung von
die der Bewertung von ![]() zugrundeliegende Evidenz ist.
zugrundeliegende Evidenz ist.
Der im Rahmen der Abarbeitung der Regeln erstellte Und-Oder-Kombinationsgraph ist in Abbildung 6.7 dargestellt.
 |
6.8.1 Das mathematische
Modell
Der Certainty Factor gibt ein Maß für das Vertrauen in den
Wahrheitsgehalt eines Faktums an. Da es jedoch in vielen Fällen einfacher
ist ein Maß für das Vertrauen bzw. das Mißtrauen in eine Aussage
anzugeben, als direkt den Certainty Factor zu bestimmen, basiert die in
MYCIN getroffene Definition auf zwei weiteren Größen: dem Maß des
Mißtrauens (measure of desbelive)
| ,,Im Fall der Evidenz E wächst
das Vertrauen, daß | ||
| ,,Im Fall der Evidenz E wächst
das Mißtrauen, daß |
Der Certainty Factor ![]() wird dann über die normierte Differenz der Maße
wird dann über die normierte Differenz der Maße ![]() und
und ![]() berechnet:
berechnet:
Die Sicherheit zusammengesetzter Aussagen
Für den Fall, daß die Prämisse einer Regel aus der booleanschen Verknüpfung von Fakten besteht, wird der Certainty Factor der Prämisse durch die Maximums- bzw. Minimumsbildung bestimmt: [Heinsohn1999]| (6.2) | |||
| (6.3) |
Anwendung von Regeln
Die Anwendung einer Regel, welche mit einem festen Certainty Factor versehen ist, und deren Prämisse mit einem dynamischen Certainty Factor bewertet ist, führt zu einer Bewertung der Hypothese, auf die geschlossen wird. Dabei müssen der Certainty Factor der PrämisseFür den Fall, daß die Prämisse einer Regel mit einem negativen Certainty Factor bewertet ist, darf diese Formel nicht angewendet werden. Diese Vorgehensweise wird einsichtig, wenn man voraussetzt, daß jede angewendete Regel eine, zumindest zu einem bestimmten Grad, erfüllte Prämisse besitzen muß. Für eine negative Prämisse ist diese Voraussetzung nicht erfüllt. Somit darf diese Regel nicht angewendet werden. [Heinsohn1999]
Parallel Kombination
Wird eine Hypothese von mehreren Regel bewertet, so müssen diese Bewertungen zu einer Gesamtbewertung zusammengeführt werden. Dies geschieht mit Hilfe der parallelen Kombination. Wird eine HypotheseSeien ![]() und
und ![]() , dann gilt
, dann gilt
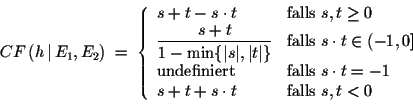
Die oben definierte Funktion für die parallele Kombination ist sowohl kommutativ, als auch assoziativ. Das Ergebnis der Kombination ist somit unabhängig von der Reihenfolge, mit der die entsprechenden Certainty Factors kombiniert werden. Auf diese Weise können durch hintereinander Anwendung der Formel 6.5 auch die Certainty Factors mehrerer Hypothesen kombiniert werden.
Eine wichtige Eigenschaft der Formel 6.5
ist, daß die Kombination mit einer ,,leeren'' Informationsquelle
(mit ![]() ) keine Änderung am
Gesamt-Certainty Factor hervorruft. [Heinsohn1999]
) keine Änderung am
Gesamt-Certainty Factor hervorruft. [Heinsohn1999]
Rechenbeispiel
Die Anwendung der oben angeführten Rechenvorschriften für die Propagierung von Certainty Factors sollen nun anhand eines konkreten Zahlenbeispiel veranschaulicht werden. Als Regelbasis sollen folgende Regeln dienen: [Heinsohn1999]
| Regel 1: | |||
| Regel 2: | |||
| Regel 3: |
|
|
| 1 | 1 | 0.6 | 0.5 | 1 | 0.5 | |
| 0.2 | 0 | 0 | 0.5 | 0 | 0 | |
| 1 | 1 | 0.6 | 0 | 1 | 0.5 |
| Regel 1: | |||
| Regel 2: | |||
| Regel 3: |
Im nächsten Schritt fließen in die Anwendung von Regel 1 die
Regelgewichtung ![]() und die Prämissensicherheit
und die Prämissensicherheit ![]() ein. Unter Anwendung von Formel 6.4
erhält man:
ein. Unter Anwendung von Formel 6.4
erhält man:
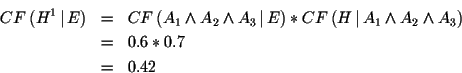
und für Regel 3
Man beachte, daß der negative Certainty Factor von Regel 3 zu einer
negativen Gewichtung des
Wertes ![]() geführt hat. Durch die
Regelabarbeitung haben wir nun drei unabhängige Bewertungen für
geführt hat. Durch die
Regelabarbeitung haben wir nun drei unabhängige Bewertungen für ![]() erhalten.
erhalten.
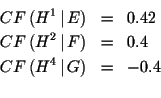
Diese müssen jetzt durch parallel Kombination zu einem Wert
zusammengeführt werden. Dies erfolgt mit Hilfe der Gleichung 6.5.
Im ersten Schritt werden die ersten beiden Informationen kombiniert.
Dieses Ergebnis wird nun
mit ![]() kombiniert.
kombiniert.
Nach Abarbeitung aller Regeln erhält man somit für die Bewertung
der Hypothese ![]() den Certainty Factor
den Certainty Factor ![]() .
.
In diesem Abschnitt wurden die Certainty Factors als Möglichkeit vorgestellt, unsicheres Wissen in einem wissensverarbeitenden System zu speichern und zu verarbeiten. Im nachfolgenden Abschnitt wird einen weitere Möglichkeit beleuchtet, unsicheres Wissen zu verarbeiten. Die vorgestellte Methode der Fuzzy Logic beruht dabei auf der Verwendung von unscharfen Mengen.
Gerald Reif
2000-02-01